
実際に記憶装置の上で情報を保持するための仕組みとして「変数」というものを
学びました.数値などの値を1つ保持するには変数を用意するだけで十分なのですが,
たとえば
「たくさんの値をまとめて保持しておきたい」
といった場合は,変数を使用するだけでは不便です.
(たくさん変数を宣言するのも大変面倒なことになります)
そこで,変数よりももっと高度なデータ管理の仕組みが求められます.
たとえば表計算ソフトのスプレッドシートのように,たくさんの値をまとめて
保持する「配列」というデータ管理の仕組みもあります.
配列の他にも,「スタック」「キュー」「線形リスト」といった,多数のデータを整然と
保持するためのデータ構造があります.
ここでは,実用的なアプリケーションプログラムを作成するために是非学んでおいて
ほしい基本的なデータ構造について説明します.
(最初の例題)
複数の数値がある場合に,その中で最も大きい値(最大値)を求めるプログラムについて
考えてみましょう.
プログラムを作るために状況を整理します.
● 数値が a0, a0, a2, … , an と並んでいる.
● 最大値が見つかったらその値を max という変数にセットして,それを印字出力する
● 次の手順で最大値を探す
1. 一番最初の数 a0 が最大値である可能性があるので,仮に max ← a0としておく
2. max の値と次の a? の値を比較して a? の方が大きければ改めて max ← a? とする
3. 全ての a? について上の2のステップを行う.終了した時の max に最大値が入っている
この例題を考えるに当たって,まず必要になるのが「複数の値」を保持しておく機構で,
早速「配列」が登場します.
配列をはじめとする各種オブジェクトを生成するには,基本的に次の2つのステップを踏みます.
1. オブジェクトの型の宣言
2. オブジェクトの生成
例えば,複数の整数値を格納する配列 a を宣言するには,
int[ ] a;
あるいは,
int a[ ];
と "[ ]" を付けて宣言します.この段階では,変数の名前のみが宣言されただけで,
次に,「実際に何個の数値を格納するか」を決定する必要があり,次のようにします.
a = new int[20];
この例では,20個の値を格納する配列ができたことになります.
この "new" という記述により,実際にコンピュータの主記憶上に整数値を20個格納する
記憶域が確保され,それが変数名 a に割り当てられたことになります.
これまでも new という記述が出てきましたが,これは主記憶装置上に実際に使用する領域を
確保するためのものです.
配列の生成は,簡単のために次のように記述することもできます.
int[ ] a = new int[20];
あるいは,
int a[ ] = new int[20];
さて,話を例題に戻しましょう.次のプログラム "Getmax.java" を見てください.
このプログラムは乱数を20個生成して,その中から最大のものを探すというサンプルプログラムです.
3行目と5行目で配列aを用意しています.
「配列aのn番目」は a[n] と表します.
このプログラムでは,7行目から10行目にかけて,乱数を20個発生してそれを配列aにセットしています.
(乱数の生成については次の説明を参照のこと)
上のプログラムの8行目では,Math.random() を 100倍し,0以上100未満の乱数を生成しています.
この Math.random() は double 型の乱数を生成するので,小数点以下を切り落としてて整数の値に
変換するために (int) という記述をしています.このようにして値の型を変換することをキャスト
といいます.
12行目から17行目にかけて,最大値を探す処理をしています.
(配列の添字に関する注意)
配列変数の添え字は0から始まります.今回のプログラムでは配列の要素の数は20ですが,添字は0から
始って19で終わります.
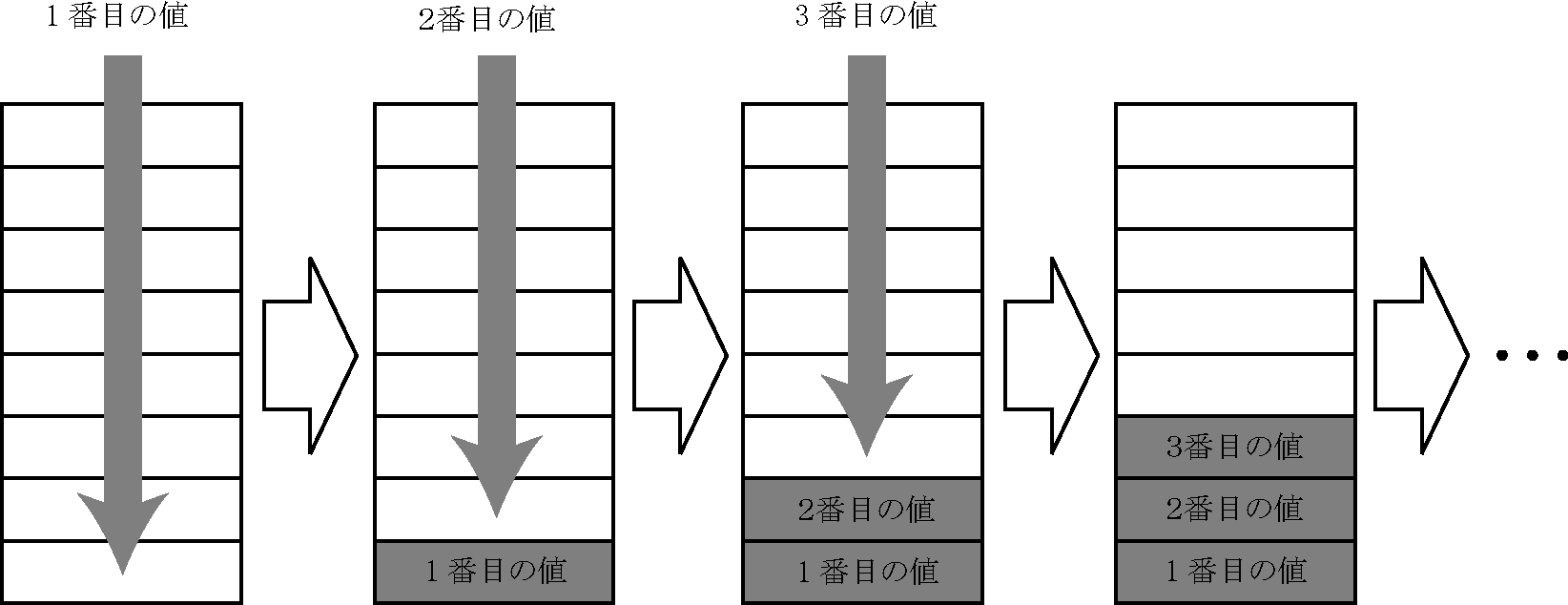
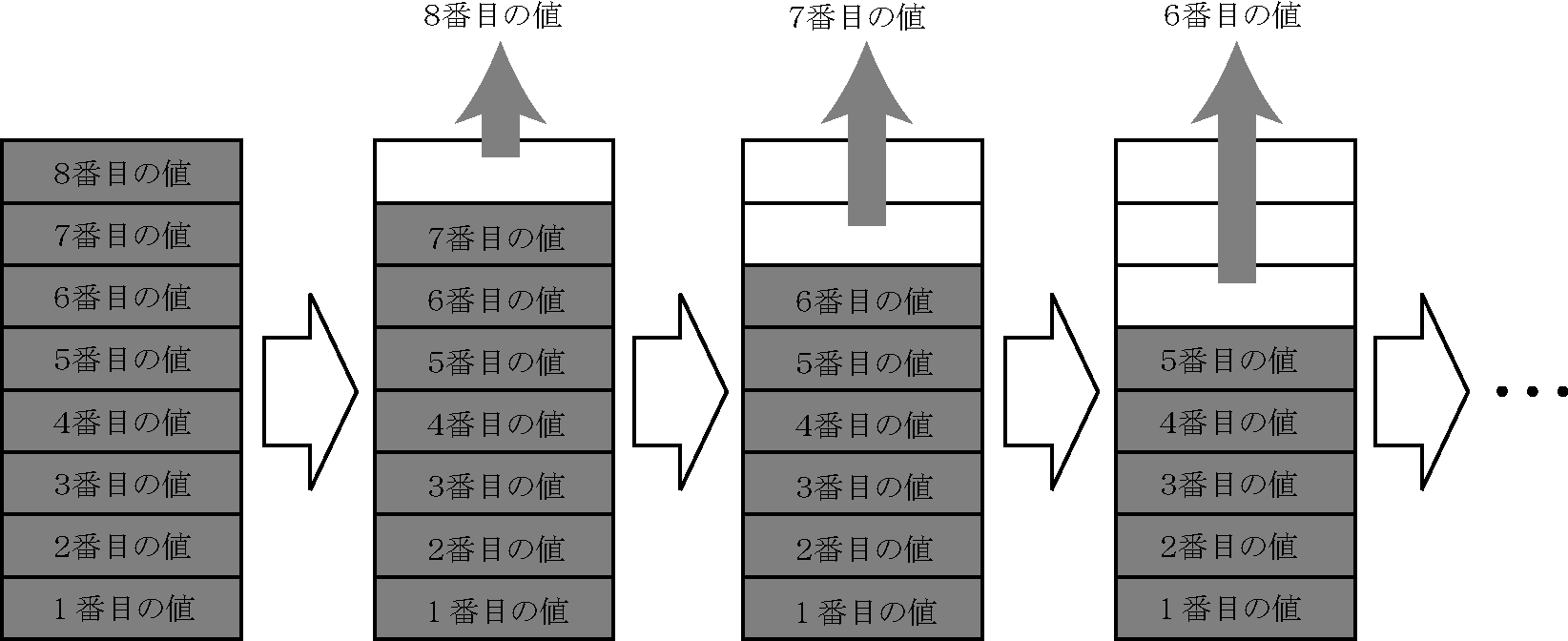
スタックは,データの蓄積と取り出しを行う機構です.データの取り出しは新しいものが優先されます.
このような蓄積の形態を後入れ先出し(LIFO:Last In First Out)といいます.スタックにデータを
蓄積する操作を「push」といいます.(下図)
また,スタックからデータを取り出す操作を「pop」といいます.(下図)
(スタックの要素)
スタックを構成するのに必要な要素は
(1) 配列などのデータを複数格納する記憶構造(添字つき)
(2) 最新の値が入っている場所を示す「スタックポインタ」
(3) ポインタの最大値を格納する変数
です.(下図)
(スタックに対する操作)
スタックには次のような3つの操作を行います.
(0) 初期化
スタックポインタを -1 にして「空」の状態にする.
(1) データの蓄積(push)
スタックポインタの値を1つ増やし,スタックポインタの示すスタックにデータを格納する.
ただし,スタックポインタが最大値になっておればデータの格納は失敗する.
(エラー:スタックオーバーフロー)
(2) データの取り出し(pop)
スタックポインタの示すスタックからデータを取り出し,スタックポインタの値を1つ減らす.
ただし,スタックポインタが-1 であれば,スタックは空であり,データの取り出しは失敗
する.(エラー)
(次の「オブジェクト指向」のページで,実際にスタックを作って動作させるプログラムを作ります)
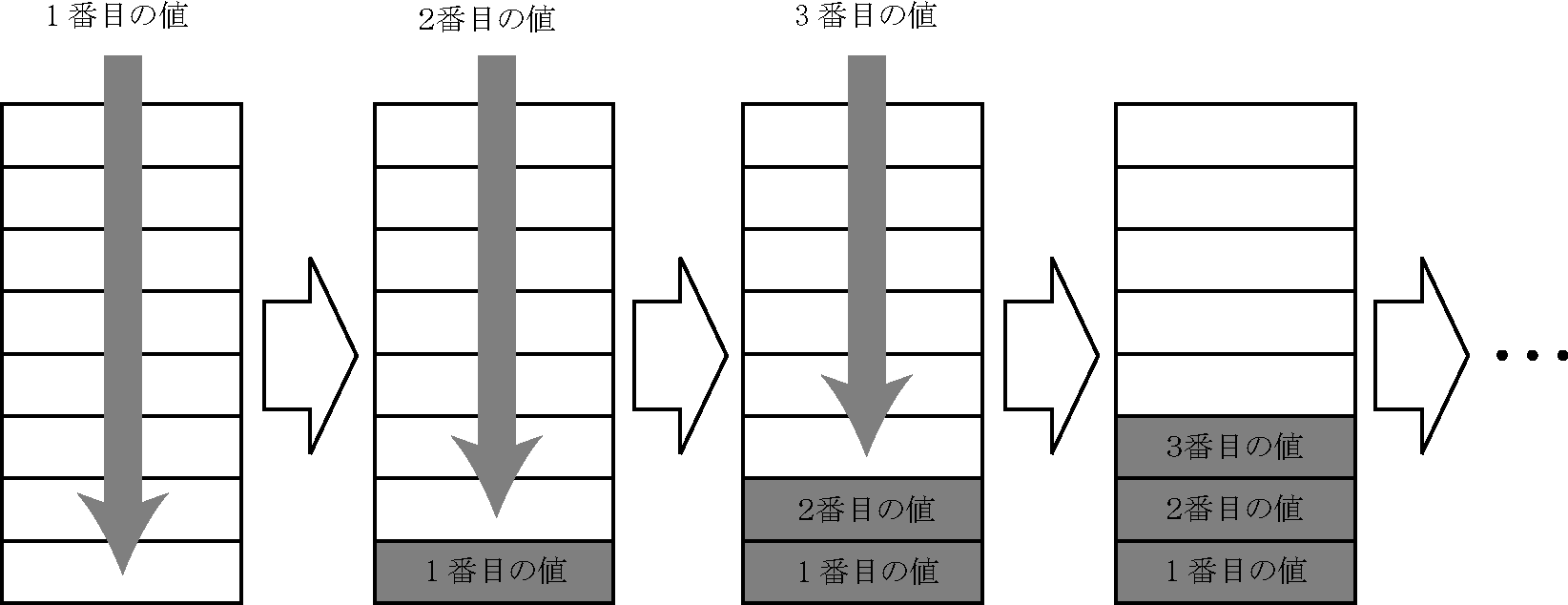
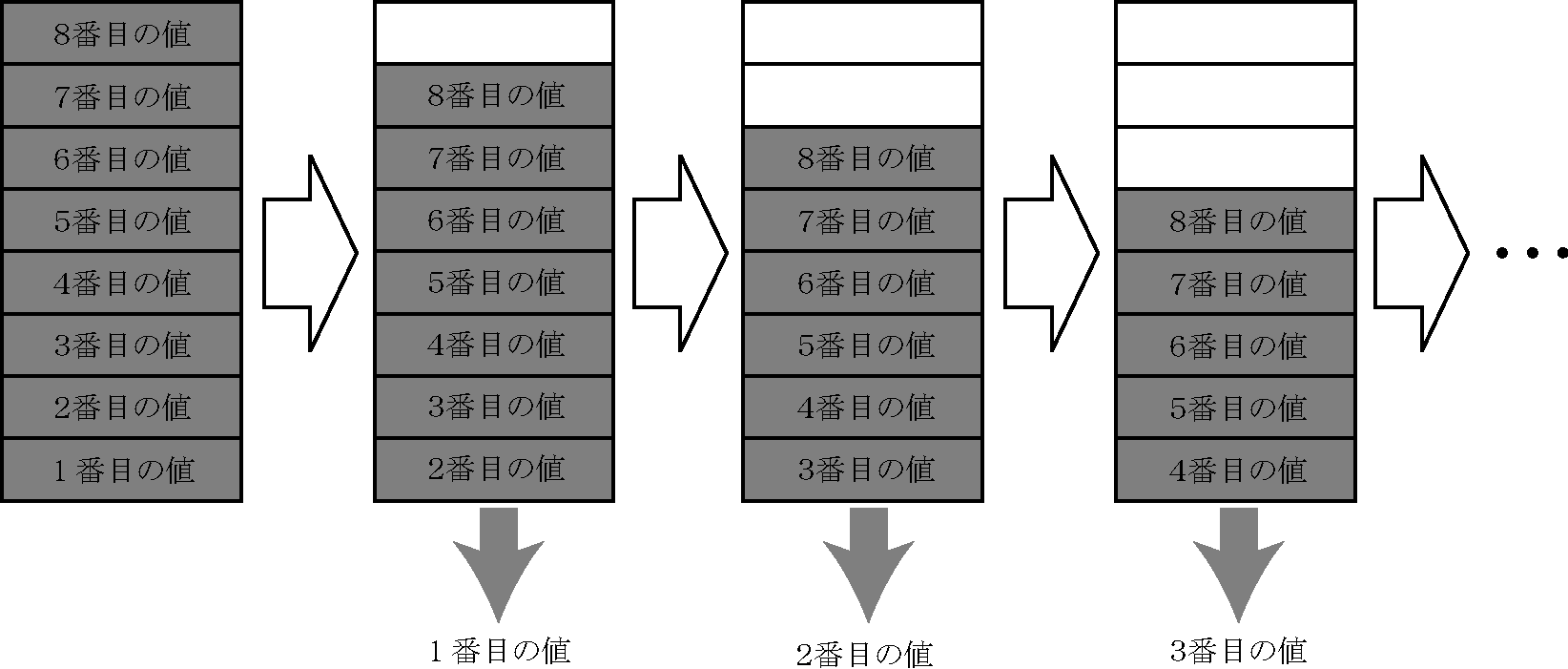
キューは,データの蓄積と取り出しを行う機構です.データの取り出しは古いものが優先されます.
このような蓄積の形態を先入れ先出し(FIFO:First In First Out)といいます.キューにデータを
蓄積する操作を「enqueue」といいます.(下図)
キューからデータを取り出す操作を「dequeue」といいます.(下図)
(キューの要素)
キューを構成するのに必要な要素は
(1) 配列などのデータを複数格納する記憶構造(添字つき)
(2) 最後の値が入っている場所を示す「ポインタ」
(3) ポインタの最大値を格納する変数
です.(下図)
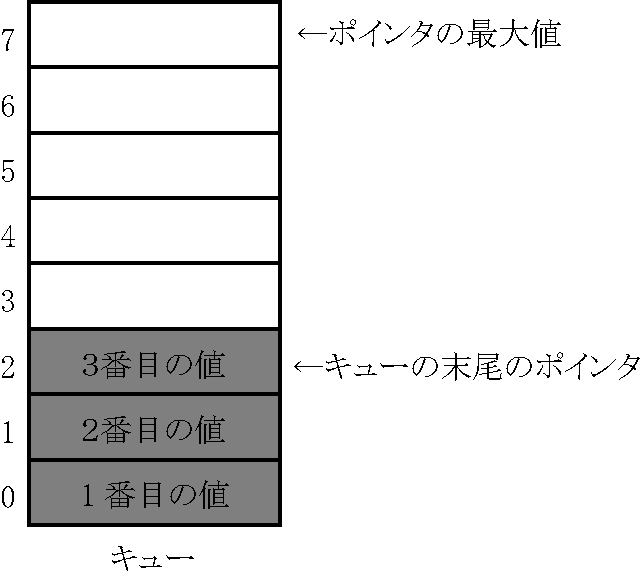
(キューに対する操作)
(0) 初期化
ポインタをは -1 にして「空」の状態にする.
(1) データの蓄積(enqueue)
ポインタの値を1 つ増やし,ポインタの示すキューにデータを格納する.
ただし,ポインタが最大値になっておればデータの格納は失敗する.(エラー)
(2) データの取り出し(dequeue)
キューの0 番目からデータを取り出し,キュー全体の内容をポインタの1 つ低い位置に移動する.
この後ポインタの値を1 つ減らす.ただし,ポインタが-1 であれば,キューは空であり,データ
の取り出しは失敗する.(エラー)
複数のデータを取り扱う場合は配列を用いることができますが,データが多量でしかも,
扱うデータの個数が予めわからない場合は,配列を用いると記憶域が無駄になることが多いです.
そのような場合,リストと呼ばれる記憶構造を用いるのが良いです.
下に最も単純なリスト構造である線形リストの構造の概略を示します.
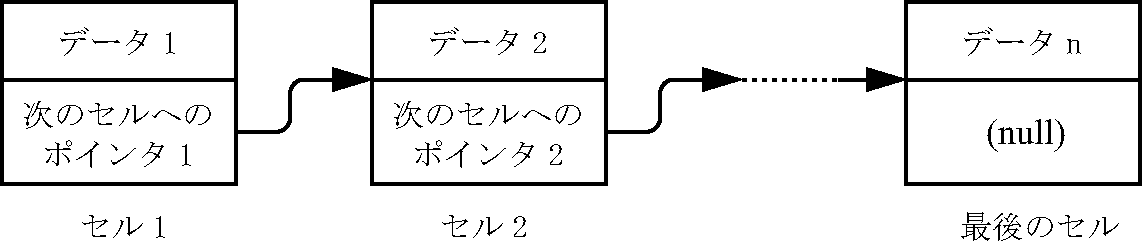
データはセルと呼ばれる記憶単位に格納されます.各セルには,次のセルを指し示すポインタがあり,
最後のポインタは "null"(空を意味する記号)が格納され,以降にセルが無いことを意味します.
リストでは,格納すべきデータが発生するたびにセルが割り当てられて既存のリストに追加接続されます.
つまり,必要に応じて順次記憶が割り当てられるので,記憶域が無駄になることがありません.
(次の「オブジェクト指向」のページで,実際にリストを実現するプログラムを作ります)